- World of DaaS
- Posts
- Unlocking the Future of Data Monetization
Unlocking the Future of Data Monetization
The Rising Value of Specific Insight
Today, data companies successfully monetize their data when it can be used to support a purchaser’s business decisions. Just look at the World of DaaS public Data as a Service companies list, and you can see this pattern across data companies that have accrued the most market capitalization. First, there are data providers that sell to financial institutions. As an example, take ratings agencies and index providers: these datasets allow asset managers to sell financial products and corporates to sell debt instruments. Market data allows asset managers to manage financial products and risk data allows investors to calibrate their investments and insurance contracts. The common denominator is information driving financial transactions.
Then there are data providers that sell to specific business verticals: healthcare data providers which allow pharmaceutical companies to make better research investments, or real estate data providers which allow commercial real estate participants to better assess and transact real estate value. It extends to enterprise sales, with contact databases allowing sales teams to accelerate B2B outreach. All of these data verticals sell to the enterprise, and their value proposition serves a business need.

it’s a data jungle out there
But this is only a small sliver of the data generated online, much of which is spread across private companies. The long tail of internet data is left with a much weaker monetization engine: advertising. Since the early days of the internet, all advertising roads have led to Google, and monetization has been a numbers game: drive traffic, ideally cater to a target audience, increase CPM value, and optimize SEO. This has been the status quo for the last 25 years. But recently, we’ve noticed a change. That change interestingly started with Google.
Reddit's Google Deal: Exclusive Search Rights and the New Data Walls
Let’s start with Reddit’s licensing agreement with Google struck back in February 2024. Initially billed as an LLM training license, recent reporting suggests the $60 million annual deal also involves an exclusive rights package for search results. Reporting by 404 media uncovered the added wrinkle, where Reddit has stealthily begun to block other search engines from crawling their site. As noted, “there’s been a huge increase in the number of websites that are trying to block bots that AI companies use to scrape them for training data.” This is creating walled gardens of data across the internet.
This is a curious development for a social media company: exclusively partnering with the proverbial monopolist in the search market. As we alluded to earlier, if your data isn’t facilitating a customer’s financial transaction, it is best monetized through advertising. While Reddit may pursue selling its data via an API to firms keenly focused on sentiment analysis (e.g., hedge funds trawling r/wsb), over 90% of Reddit’s current revenue comes from advertising. Advertising works best when reaching the widest audience. While Google represents ~90% of the search market share, it fundamentally wouldn’t make sense to foreclose on the other 10%.
One rationale might be that Reddit has leverage over Google to extract superior monetization for their data vs traditional advertising. This is a function of competition to Google search brought on by LLMs catering to knowledge queries. Google understands their impact on the vast amount of SEO and CPM optimization across the web. Over the years, this has led to a deterioration in the quality of search results for common questions. Google results are too often routed to optimized clickbait sites instead of tangible solutions, poisoning the proverbial well. Pair that with increasing ad loads, and you have an existential threat to Google given the deterioration in the search experience. Google needs to capture a specific source of insight for its queries to increase the quality of search response. With LLM services such as ChatGPT and Perplexity making headway into a different workflow for information seekers, Google needed to react.
Interestingly, their reaction reveals a new revenue opportunity for data: data which powers LLM intelligence. Even though the deal is tied to old-world search, the value extraction is driven by the competitive threat posed by LLMs. Unlike a dataset which gets brokered on a financial data marketplace, data which can deliver subject-matter expertise, timely relevance, or added training benefit to an LLM will become increasingly valuable.
Trends in the AI Landscape Shaping Data Value: Competition, Convergence, and Compute
Besides the existential worry brought on by competition for Google search, there are several interesting developments across the foundational model space catalyzing this change. First, there has been a convergence of sorts, as the difference in model performance across open and closed source LLMs has become less pronounced. Just recently, Meta announced its LLAMA 3.1 open source model which performs almost in line with the current cutting edge from OpenAI and Anthropic. Only 12 months ago, OpenAI had what felt like an unassailable lead versus open source (e.g., GPT 4 vs LLAMA 2, see below). Since then, performance has narrowed:
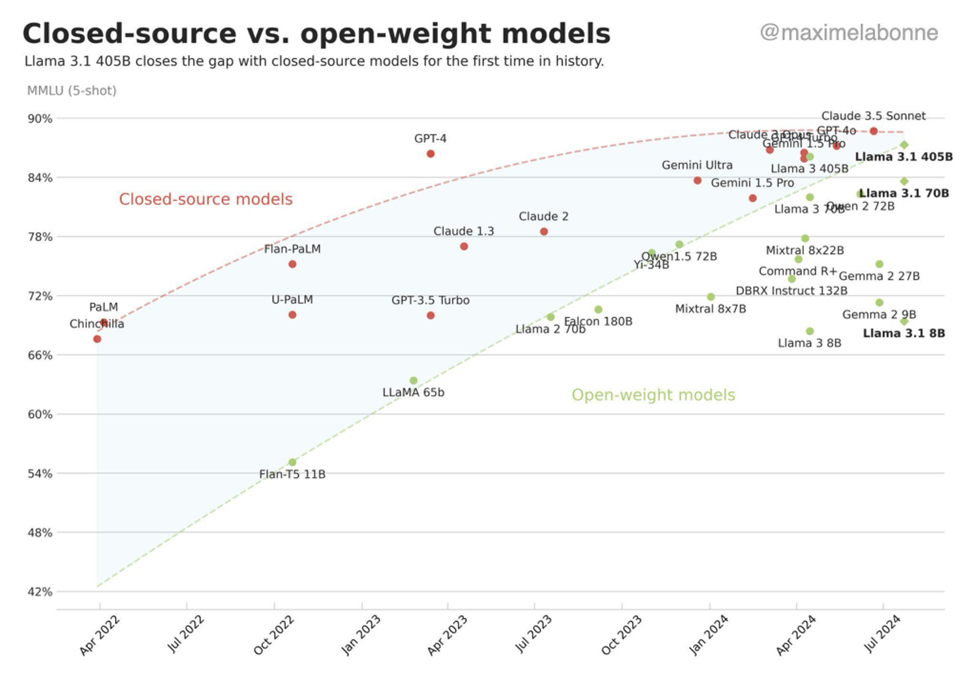
Second, a push for synthetic data sources to deliver more training improvement seems to be faltering. A recent paper by researchers from Oxford University has found significant problems with LLM performance when synthetic data is inserted into the training process. The researchers found “irreversible defects in the resulting models” which they refer to as “model collapse.” What felt like a workaround from pesky pushback from the likes of the NY Times feels more like a closing door.

Third, the worst of the NVIDIA GPU bottlenecks appears to be easing, with a greater focus on downstream issues like power consumption. This means that most of the hyperscalers will be able to throw as much compute as they can afford (and they can afford a lot!) at building their next generation models. This further reduces the lead that first movers had by securing scarce compute, potentially creating less product differentiation.
Ultimately what this points to is the growing importance for the data side of the training and retrieval equation. And if the Reddit deal shows us anything, it is that unique datasets that draw answers to questions, have subject matter expertise rich information, or provide enterprise specific use cases of Gen AI will become increasingly valuable.
Monetizing Data: The Rise of Specific Intelligence in the Gen AI Value Chain
Stepping back to our initial claim that the best way to monetize data was to add value to a company in making a business decision, perhaps we’ll have a new pillar of monetization potential: data that assists in improving specific intelligence for Gen AI. This Gen AI will be plugged into every cloud computing layer, every enterprise software package, and many enterprise workflows.
Note the word specific instead of general. Every LLM is now trained on Wikipedia and Creative Common datasets that are readily accessed across the internet. But as LLMs need to solve enterprise specific problems to attack the business use cases which are underwriting their massive capex expansions, datasets that allow these models to develop the right enterprise answers will become increasingly valuable.
And so, we should expect to see a growing balkanization of datasets across the internet. It is becoming increasingly apparent that allowing search engines free reign to index and then all-too-often ingest information into their LLMs (for the sake of better web traffic) is a poor value proposition for data which can power specific intelligence.
Data Marketplaces: The Bridge for Monetizing Valuable Insights
Not every company has the scale or negotiating clout to achieve what Reddit did, even if their data is extremely valuable in the right hands. There is still a discovery problem. Foundational model companies will likely start negotiating with reputable news sources or social repositories. They may even focus on walled scientific datasets. At least in the short term, the best path for data monetization in a fractured landscape will likely be data marketplaces, which are growing at a rapid clip across various industries and verticals.
While many of these marketplaces cater towards the old way of facilitating business decisions, new venues with new ways of thinking about data are proliferating. This is unlocking paths to monetization for valuable datasets. Take Carbon Arc as an example. Their novel approach promotes data exchange based upon the insight the data provides. While this has narrowly been conducted through marketplaces that evaluate alternative datasets for say financial investment decisions, the process is very laborious, requiring the buyer to scope and backtest the data on their own in order to underwrite a purchasing decision.
Imagine a car buyer running the same safety and performance tests that JD Power does today. That is the state of many data markets today. As liquidity and protocol in data markets improve, that status quo will change. Today, only a narrow subset of the vast amount of insight can be fed into specific intelligence solutions like LLMs. Expect this opportunity to grow exponentially and for billion dollar companies to blossom, providing the new protocols for valuing intelligence (e.g., ratings agency) and the liquidity for its efficient brokerage (e.g., stock exchange).
In a follow on piece, we’ll provide a blueprint for the rapidly evolving landscape of data marketplaces and how this should shape the evolution of data monetization. One thing is clear. The fact that Google was willing to pay $60 million per year for well classified social discussion that it previously would have free access to indicates a growing truth: the amount of revenue that will become available to unique data providers that fill specific intelligence is set to explode.
Reply