- World of DaaS
- Posts
- AI is a $200 billion market for data providers
AI is a $200 billion market for data providers
Alkemi's CEO Connor Folley on AI's evolution and how the shift to pre-trained models has created a market 10x the expected size.
Connor Folley
January 14, 2025

The release of ChatGPT in November 2022 triggered a fundamental shift in how businesses approach AI and sparked a surge of AI applications that demonstrated the potential of foundation models trained on vast datasets. Initial predictions suggested every company would need massive training datasets. Reality proved different. Today's AI landscape reveals a more nuanced picture—one that creates unprecedented opportunities for data providers who can adapt to evolving market demands.
AI Expectations vs. Reality
The first wave of AI adoption, what Sequoia Capital dubbed “AI’s Act One,” focused on technical possibilities. Companies rushed to demonstrate what they could do with foundation models, leading to a flurry of novel applications. These early demonstrations led industry experts to predict that every company would acquire massive data sets to train their own large language models (LLMs). These early expectations transformed priorities, roadmaps, and budgets across industries. But, as the dust settled, a more practical "Act Two" emerged, driven by customer needs rather than technological novelty, and many of those initial investments proved missteps.
“AI’s first year out the gate—“Act 1”—came from the technology-out. We discovered a new “hammer”—foundation models—and unleashed a wave of novelty apps that were lightweight demonstrations of cool new technology. We now believe the market is entering “Act 2”—which will be from the customer-back. Act 2 will solve human problems end-to-end.”
This second phase introduced the modern AI stack, democratizing tools like retrieval-augmented generation (RAG) and empowering 30 million mainstream developers. These frameworks allow AI applications to access external knowledge bases in real time, dramatically improving their ability to provide accurate, contextual responses. Over the following year, businesses embraced AI at an unprecedented rate, drawn by promises of productivity gains and a competitive edge. The tech industry reoriented its focus to meet this demand, targeting practical, customer-centered solutions to real-world use cases.
The New Reality of Democratized AI
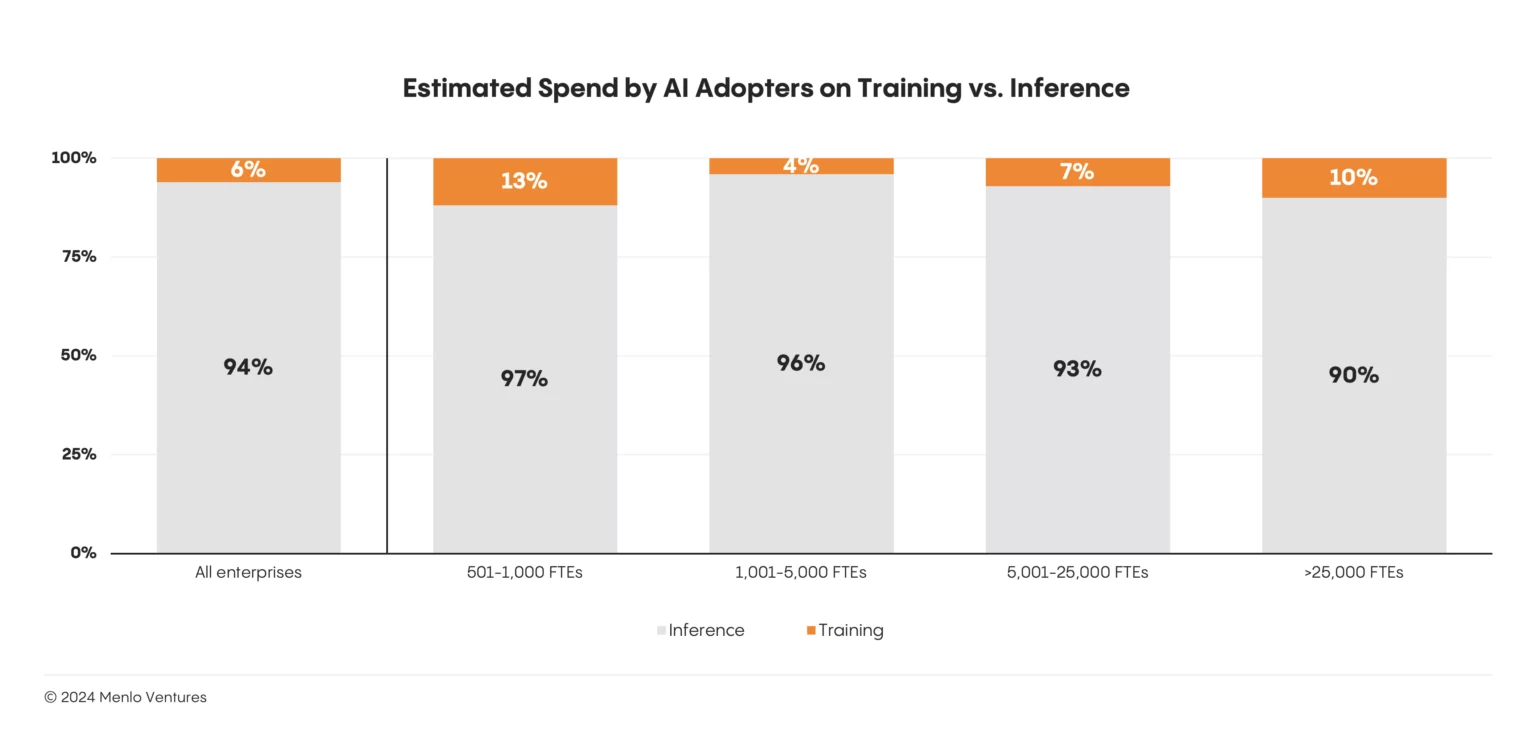
The democratized nature of the modern AI stack radically shifted the data market, and the numbers tell a compelling story: fewer than 10% of enterprise AI projects today involve training models. Instead, organizations are leveraging existing, pre-trained models from OpenAI, Google, Anthropic, and others and making them more intelligent by connecting them with relevant data sources to deliver domain-specific intelligence.
This model-as-a-service approach departs from the initial predictions of AI’s Act One. With powerful pre-trained LLMs, RAG frameworks, and advanced orchestration tools, developers can now achieve what once required years of expertise and fundamental research in days or weeks.
“In the early days of the LLM revolution, it seemed possible that every company might one day train their own large language model. Models like BloombergGPT, a 50-billion-parameter LLM trained specifically on financial data released in March 2023, was heralded as an example of the flood of enterprise and domain-specific LLMs to come. The expected deluge never materialized. Instead, Menlo Ventures’ recent enterprise AI survey indicates that almost 95% of all AI spend is on run-time vs. pre-training.”
This shift to pre-trained models has fundamentally changed how AI applications are built and deployed. By 2023, over half of AI applications relied on orchestration tools like LangChain and LlamaIndex to refine model reasoning and incorporate external data via RAG frameworks. With these orchestration tools becoming central to the modern AI stack and off-the-shelf models obviating the need for training data, 95% of AI spending shifted to inference. (AI inference is when a trained AI model is used to reason and draw conclusions based on new input data. RAG frameworks incorporate external knowledge to generate better responses during the inference stage.)
This shift has also created a data market that is ten times larger than initially anticipated, and developers have equipped themselves with the picks and shovels to stake their claim on a $200 billion market.
Today, that market consists primarily of individual developers who need flexible access to high-quality data. Every data buyer is a builder, empowered to evaluate and purchase the tools and data they need to do the job. They're not looking to build massive training datasets—they need efficient ways to connect AI applications with relevant information on demand. However, most data providers still package, sell, and deliver their offerings for a training data market that never materialized, creating bottlenecks that restrict developers’ access to essential data.
The Disconnect: How Traditional Data Delivery Models Hold Back Innovation
“The three pillars of data businesses: Acquisition, Transformation, and Delivery”
This fundamental misalignment between what data providers can sell and what developers need creates significant challenges:
Time and Resource Drain
The inefficient delivery of data products today demands excessive time and budget from AI developers. The cost of data preparation often exceeds—sometimes by 2x—the costs of the initial data set. Developers would much rather spend their resources building and improving apps (and budget data providers would no doubt rather see it spent on more data).
Integration Challenges
For a data business, the method by which you deliver the data is as critical a factor to product-market-fit as any other. API-based services comprise 83% of internet traffic, enabling data to be efficiently delivered, evaluated, and experimented with. Yet, existing API technology is incompatible with RAG frameworks, causing developers to spend over 24% of their time preparing and ingesting bulk data.
Rigid Packaging Models
Developers value efficiency and thus loathe time-consuming enterprise sales models. Yet, because providers must deliver data products in bulk, they include complex annual licenses that average $186K. Developers waste over 26% of their time and budget sourcing data, making it the most expensive and time-consuming stage of AI development. This is an antiquated barrier for developers who need more flexible, consumption-based access to data.
Lessons from Cloud Computing’s Evolution
Training AI models requires significant upfront fixed costs, but pre-trained models offer developers a variable cost structure, reducing financial barriers to entry and accelerating adoption. Similarly, AWS shifted and enlarged the computing market by offering a variable cost structure for cloud services. AWS’ cost structure innovation rippled throughout the stack, forcing every other vendor to adopt a variable cost structure to accommodate the demands of a larger market. Software was no exception; vendors adopted a SaaS model, and the market boomed.
The data market is at a similar inflection point. Data providers who take inspiration from these platform-level innovations and experiment with flexible data packaging stand to capture a disproportionate share of this expanding market.
The Path Forward
As AI continues its evolution from technological novelty to practical business tool, data providers must evolve as well. Until AI systems have more efficient ways to access and integrate high-quality data, these data access barriers will continue to limit developers and restrict revenue opportunities for data providers. To unlock AI’s $200 billion market, data providers must adapt to serve the needs of the modern AI stack:
Flexible delivery mechanisms that seamlessly integrate with modern AI frameworks
Consumption-based pricing that aligns with developers' actual usage patterns
Streamlined tools for AI applications to access and integrate external data sources
Enhanced transparency and control over how data gets used
API-first architecture designed specifically for AI applications
Alkemi was founded to eliminate data access barriers and make it easy for AI developers to integrate the data they need.
The company bundles everything a data provider needs to deploy, manage, and sell programmatic data access to AI developers. Compatible with popular AI platforms and plugins, Alkemi allows AI applications to consume data on-demand, offering providers flexibility in how they package and sell their data. Through Alkemi, providers gain transparency and control over data usage, empowering them to capitalize on AI opportunities without compromising their intellectual property.
The data providers who thrive in AI's Second Act will be those who recognize that the method of delivery has become as crucial as the data itself. Alkemi is on a mission to put world-class data into the hands of those who can build something amazing.
Connor Folley is the CEO of Alkemi
Reply